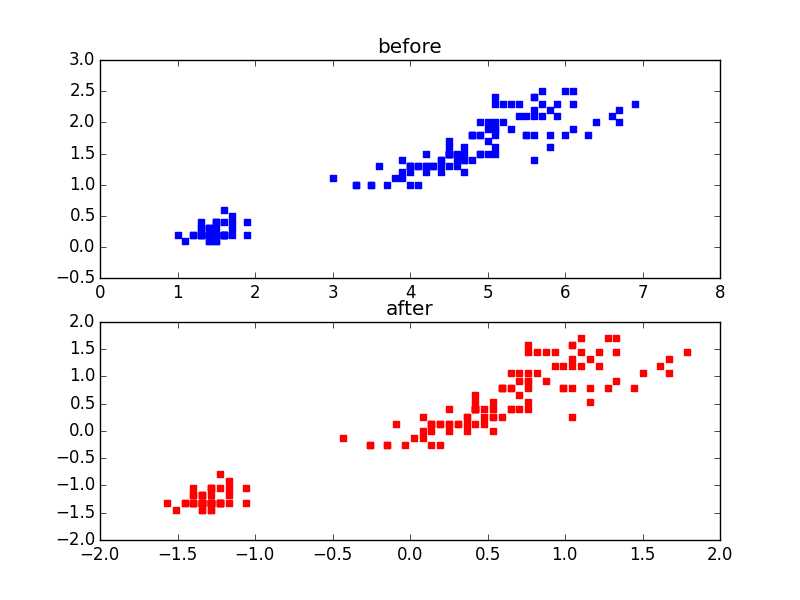
#!/usr/bin/python# -*- coding: utf-8 -*-importpandas.rpy.commonasprcimportnumpyasnpfromscipyimportstatsimportmatplotlib.pyplotasplt#各種毎に違うMarkerをつけるための関数を作りたかった#(上手くできず挫折)if__name__=='__main__':x=prc.load_data("iris")printxx=np.array(x)#print x print"--"#0.Sepal.Length #1.Sepal.Width #2.Petal.Length(花弁の長さ)#3.Petal.Width(花弁の幅)#4.Species#平均値pl=np.array(x[:,2],dtype=float)print"Petal.Length Average "+str(np.average(pl))pw=np.array(x[:,3],dtype=float)print"Petal.Width Average "+str(np.average(pw))word=np.array(x[:,4],dtype=object)#共分散行列conv=np.cov(x[:,2:4],rowvar=0)print"Convariance matrix\n"+str(conv)plt.axis('scaled')#標準化前plt.subplot(211)plt.title("before")plt.scatter(x[:,2],x[:,3],marker='s',color='b')#標準化後z=np.array(x[:,2:4],dtype=float)z=stats.zscore(z,axis=0)#標準化plt.subplot(212)plt.title("after")plt.scatter(z[:,0],z[:,1],marker='s',color='r')plt.savefig("iris_43.png")#画像保存plt.show()